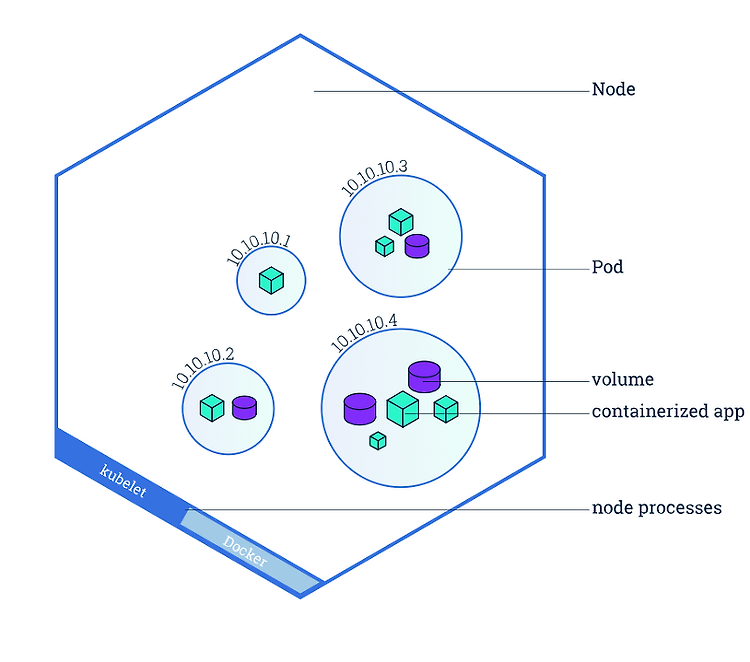
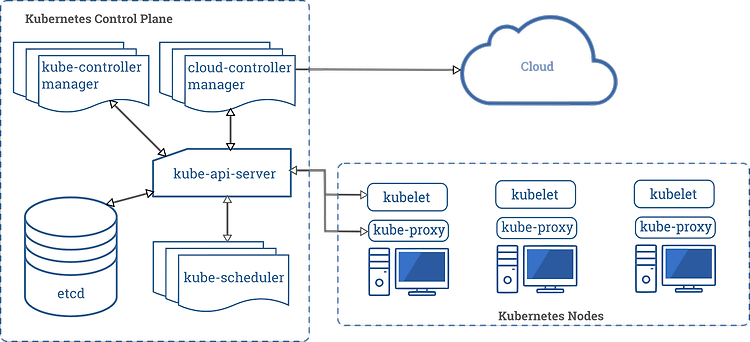
Pod란? 쿠버네티스는 컨테이너를 개별적으로 배포하는 것이 아니라 Pod라는 단위로 컨테이너를 묶어서 관리하게 됩니다. 하나의 파드는 다수의 컨테이너를 가지고 있을 수 있는데, 왜 개별적으로 하나씩 컨테이너를 배포하지 않고 여러 개의 컨테이너를 Pod단위로 묶어서 배포하게 될까요? 이와 같은 이유에는 두 가지 특징이 있습니다. Pod 내의 컨테이너는 IP와 Port를 공유합니다. 즉 두개 이상의 컨테이너가 하나의 파드를 통해 배포되었을 때 localhost로 통신이 가능합니다. Pod내에 배포된 컨테이너 간에는 디스크 볼륨을 공유할 수 있습니다. 최근 애플리케이션들은 실행할 때 애플리케이션만 올라가는 것이 아니라 로그 수집기와 같은 다양한 솔루션이 함께 배포되는 경우가 많습니다. 특히 로그수집기 같은 경..