명절에 짬을 내서 최근 공부하고 직접 구축해보았던 prometheus 포스팅을 작성해보려고 합니다. 이번 포스팅에선 Prometheus에 대한 간략한 소개와 Kubernetes 환경에서 모니터링 시스템을 구축하는 방법으로 진행해보려고 합니다. 사실 prometheus는 많은 회사에서 사용하고 있고 kubernetes의 사실상 표준 모니터링 시스템으로 사용되고 있습니다. 그럼에도 불구하고, 한국어로 된 자료가 많이 없고, 번역된 책 조차도 yes24 기준 2권밖에 존재하지 않는 기술입니다. 😭
그래서 개념만 제대로 이해하고 있다면 구축하고 사용하는 것이 그리 어렵지 않음에도 불구하고, 관련 레퍼런스를 찾기 힘들어서 helm을 사용하지 않고는 직접 구축하고 커스텀 하는 데에 어려움이 있었습니다. (저만 그런진 모르겠습니다만...)
그래서 kubernetes 환경에 prometheus를 이용해 모니터링 시스템을 구축하고 관련된 개념을 살펴보도록 포스팅을 진행해보도록 하겠습니다.
해당 포스팅에선 아래와 같은 version을 사용하였습니다.
kubernetes version : v1.17.12
quay.io/prometheus/alertmanager:v0.21.0
🧑🏻💻 Prometheus란?
프로메테우스는 SoundCloud사에서 만든 오픈소스 모니터링 툴입니다. go언어로 만들어졌으며, 지금은 독립된 오픈소스 프로젝트로 개발되고 있으며, kubernetes 환경에서 모니터링 하기 원하는 리소스로부터 metirc을 수집하고 해당 메트릭을 이용해서 모니터링하는 기능을 제공합니다. 또한 이상 증세가 발생했을 때 slack이나 여타 다른 webhook을 이용해서 알림을 주는 등 다양한 기능을 제공하고 있습니다.
prometheus에 대한 자세한 내용은 아래의 공식 레퍼런스에서 확인할 수 있습니다.
Prometheus - Monitoring system & time series database
Some of our users include:
prometheus.io
🧑🏻💻 Prometheus의 특징
1. 시계열 데이터 모델
prometheus는 key-value 쌍으로 이루어진 메트릭을 수집하여 유저에게 시계열 데이터로 제공합니다. 여기서 시계열이란 말 그대로 시간을 뜻하는 말로 '오전 6시부터 8시까지 5분 단위로'와 같은 형식으로 데이터를 제공받을 수 있습니다.
Prometheus에선 이러한 시계열 데이터를 고유하게 식별하기 위해 metric name과 label로 불리는 key-value(optional)을 사용하게 되는데 그예는 아래와 같습니다.
api_http_requests_total{method="POST", handler="/messages"}위의 데이터에서 api_http_requests_total은 metric name을 뜻하고 method="POST"나 handler="/messages"는 label입니다.
2. PromQL
이와 같이 수집된 메트릭을 유연하게 가공하기 위해 prometheus는 PromQL이라는 자체 쿼리언어를 제공하는데 문법 자체가 쉽고 간결하여 쉽게 익힐 수 있습니다. 자세한 내용은 공식 레퍼런스의 쿼리 사용법을 확인합니다.
3. 단일 노드
또한 prometheus는 분산 스토리지를 사용하지 않고 단일 노드를 사용하여 수집한 메트릭을 저장합니다. default로 15일을 저장하게 되는데 수정으로 변경할 수 있습니다.
4. Pull 방식
prometheus는 특이하게 다른 모니터링 툴과는 다르게 pull 방식을 이용합니다. 여기서 pull 방식이란 메트릭을 직접적으로 수집하는 exporter(client)에 prometheus가 직접 접속하여 수집한 메트릭을 가지고 오는 방식을 뜻합니다. 기존의 모니터링 툴들은 push 방식으로 메트릭을 수집하는 client가 서버에 메트릭을 전송하는 방식과 차이가 있습니다.
🤔Prometheus의 장단점?
- 장점
pull 방식을 사용하게 되면 모든 메트릭의 정보를 중앙 서버로 보내지 않아도 되기 때문에 부하가 높은 상황에선 fail point를 비교적 예방할 수 있습니다.
- 단점
plain prometheus를 사용하는 경우 단일 노드 구조를 가지고 있기 때문에 수집해야 할 metric의 정보와 rule이 많아질수록 configuration이 복잡지고 scale out이 어렵다는 단점이 있습니다. 이러한 경우 레퍼런스에선 prometheus를 hierarchy 구조를 만들어 사용하라고 가이드하고 있지만, 쉬운 구성방법 역시 아닙니다.
그래서 kubernetes 환경에서 여러 대의 prometheus를 사용해야 하는 상황이라면 prometheus operator와 tanos와 같은 기술들을 고려할 수 있습니다.
🧑🏻💻 Architecture
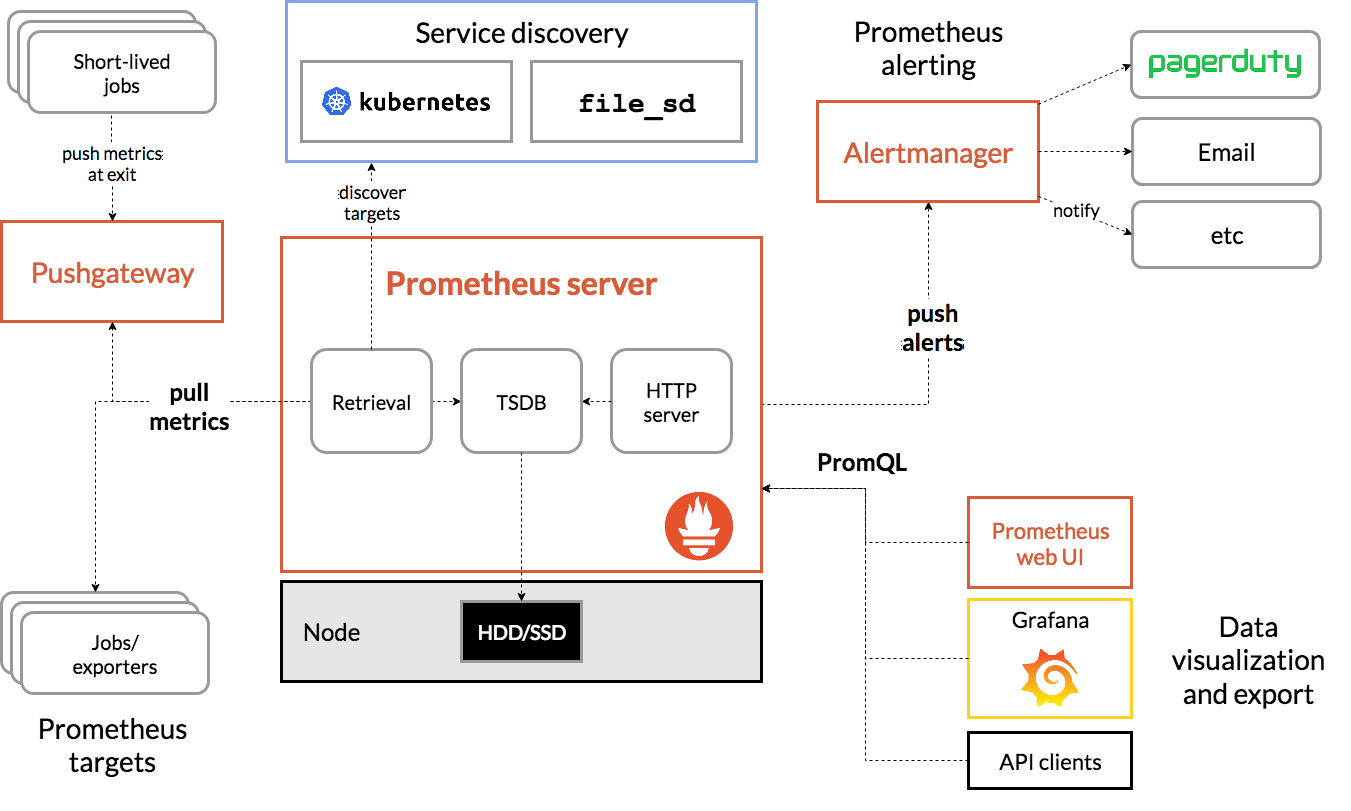
위 이미지는 promtheus 공식 홈페이지에서 가져온 promtehus architecture를 간결하게 표현한 이미지입니다. 아키텍처가 복잡해 보이지만 사실 그 구조는 무척 단순합니다. 위의 아키텍처에서 신경 써서 봐야 할 부분은 크게 5가지입니다.
1. Exporter
가장 먼저 데이터를 수집하는 exporter를 살펴보겠습니다. exporter는 실질적으로 모니터링 대상으로부터 메트릭을 수집하는 컴포넌트로 데이터를 수집하여 prometheus가 exporter로 metric을 요청 했을 때 메트릭을 전송하는 역할을 하게 됩니다.
Node-exporter를 예로 들어보자면, kubernetes 환경에 운영중인 여러 개의 node에 node-exporter가 하나씩 뜨게 됩니다. 그리고 해당 node에서 발생하는 metric (예를 들면 cpu 사용률 같은) 수집하게 됩니다. 그럼 Prometheus server는 각 node마다 떠 있는 node-exporter에게 metric을 요청하게 되고 node-exporter는 수집한 metric을 응답해주게 됩니다.
Exporter 역시 종류가 굉장히 많은데, 방금 예로 들었던 Node의 cpu, memory, bandwidth와 같은 metric을 수집하는 node-exporter부터 kafka의 상태를 체크하는 kafka-exporter, jvm에서 발생하는 metric을 수집하는 jmx-exporter 등등 정말 다양한 오픈소스 exporter가 존재합니다. 그러므로 상황에 따라 필요한 exporter를 찾아서 사용하실 수도 있고, 또는 직접 custom metric을 만들어서 수집하는 exporter를 개발하여 사용하실 수도 있습니다.
2. Prometheus Server
조금 전 exporter를 이야기 하며 잠깐 등장했던 prometheus server입니다. prometheus server는 exporter가 열어둔 http endpoint에 접속하여 exporter가 수집한 metric을 수집하고 prometheus server에 저장하게 됩니다. 이때 저장되는 metric은 분산처리가 되지 않기 때문에 단일 노드에 저장되며, prometheus는 기본적으로 15일이 지난 이전의 metric은 삭제하기 때문에, 이를 고려하여 적절한 storage 용량을 할당하는 것이 중요합니다. (retention time은 다시 다루겠지만, storage.tsdb.retention.time 옵션을 이용해서 조정할 수 있습니다.)
3. Jobs
Prometheus Server가 HTTP endpoint에 접근하여 모니터링 대상의 metric을 수집해오도록 scrape config에 metric scrape job을 등록할 수 있습니다. 이때 등록된 job은 target url에 연결된 instance들에게서 주기적으로 metric을 수집해옵니다.
때론 짧게 실행되고 종료되는 job인 경우엔 prometheus server에서 pull 하기 전에 job이 종료될 수 있습니다. 이러한 경우엔 push gateway를 사용하여 metric을 push할 수도 있습니다.
4. Alertmanager
Prometheus에선 알림이 발생하는 rule을 정의해서 해당 조건에 부합할 경우 알림을 발생시킬 수 있습니다. 예를 들어 A노드의 CPU 사용률이 90% 이상으로 그래프가 솟고 있다면 이는 조치가 필요한 상황이 되겠죠? 그러한 상황에 개발자 혹은 devops 팀 등 알림과 관련된 팀에게 선택적으로 알림을 발송할 수 있습니다.
5. Grafana
Prometheus UI만으로도 많은 시각화를 지원하지만, grafana와 같은 오픈소스 시각화 툴을 이용하면 더 다양한 시각화 기능을 사용할 수 있습니다. grafana에선 PromQL을 이용해서 Prometheus에서 시각화할 metric을 선택적으로 request 하고 이를 시각화 합니다. 또한 꼭 grafana를 사용할 필요 없이 다른 시각화 툴을 사용하거나, 직접 모니터링 시각화 툴을 개발해서 사용할 수도 있습니다.
🧑🏻💻 Prometheus 구축하기
이제 직접 prometheus를 하나씩 구성해보며 살펴보도록 하겠습니다. prometheus를 설치하는 방법은 여러 가지가 있지만, 해당 포스팅에서는 kubernetes 환경에서 docker container로 prometheus를 구성해보도록 하겠습니다. 꼭 kubernetes 환경에서 prometheus를 구성할 필요는 없지만, kubernetes와 prometheus는 대단히 궁합이 잘 맞기도 하고, 아마 이 포스팅을 찾는 대부분의 독자들이 클러스터 환경에서 prometheus를 구성할 것 같다는 예상이 되기 때문에 kubernetes 환경에서 실습을 진행하도록 하겠습니다. ㅎㅎ
참고로 kubernetes 환경이 구축되어있다는 가정하에 실습을 진행하며, 혹시 kubernetes를 아직 다뤄본 적이 없으시다면 아래의 링크에 있는 kubernetes 시리즈를 먼저 공부하고 오시는 것을 추천드리겠습니다.
[Kubernetes] 쿠버네티스의 등장 배경
※ 본 포스팅은 Network > Cloud > Docker > Kubernetes 순으로 먼저 클라우드와 인프라에 관한 전반적인 지식이 수행된 다음 읽어볼 것을 추천합니다. [Docker] Docker의 개요 Docker란 무엇일까? 개발자라면 도.
ooeunz.tistory.com
제일 먼저 kubernetes 환경에서 prometheus를 구축 및 사용하기 위해서 rbac(role-based access control)를 배포 해주도록 하겠습니다. 여기엔 Prometheus service accounts, ClusterRole, Clusterrolebinding, Namespace가 포함되어 있습니다.
# rbac.yaml
apiVersion: v1
kind: Namespace
metadata:
name: monitoring
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: monitoring
namespace: monitoring
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: monitoring
namespace: monitoring
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources:
- configmaps
verbs: ["get"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: monitoring
subjects:
- kind: ServiceAccount
name: monitoring
namespace: monitoring
roleRef:
kind: ClusterRole
name: monitoring
apiGroup: rbac.authorization.k8s.io
---
다음으로 Prometheus Configmap을 배포합니다. configmap에는 prometheus.yaml이란 파일을 포함합니다. 해당 파일에는 prometheus를 배포하기 위해 필요한 다양한 설정들이 정의되어 있습니다. 이곳에 포함되는 대표적인 설정은 아래와 같습니다.
1. global
- scrape_interval: 몇 초에 한번씩 metric을 수집할 것인지에 관한 옵션입니다. 해당 값을 설정하지 않는다면 default로 1m 값이 설정됩니다.
- scrape_timeout: metric을 scrape하는데 time out을 얼마나 둘 것인지에 관한 옵션입니다. default는 10입니다.
- evaluation_interval: 몇 초에 한번씩 규칙을 평가할 것인지 확인하는 옵션입니다. default 값은 1m입니다.
2. rule_files
- 알림을 발생시키기 위한 조건을 나열한 파일입니다. 해당 파일에 |- 를 이용해서 바로 작성해도 상관없지만, 가독성을 유지하기 위해서 해당 예시에선 /etc/prometheus-rules 하위 경로로 파일을 분리하였습니다.
3. alerting
- 위의 rule files에 명시된 조건에 부합할 경우 알림을 전송할 alertmanager의 경로를 지정하는 옵션입니다.
- 해당 예시에선 같은 monitoring이라는 namespace에 prometheus와 함께 배포할 것이기 때문에, 아래와 같이 static 경로를 잡아주도록 하겠습니다.
4. scrape_configs
- prometheus가 metric을 어떻게 scrape 할 것인지와 관련된 옵션입니다. 해당 예시는 prometheus 공식 레퍼런스를 참조했습니다. 자세한 내용은 여기를 참고하시기 바랍니다.
- 다양한 옵션들이 있지만 한 가지만 보고 넘어가자면, job_name이라는 key입니다. 이후에 prometheus를 배포하고 실제로 metric을 수집하게 되면 각 metric마다 job이라는 label이 존재한다는 것을 알 수 있습니다. 즉 다시 말해서 prometheus에선 아래의 job의 조건에 알맞게 metric을 수집하게 됩니다.
- 해당 예시에선 annotation에 `prometheus.io/scrape: "true"`가 있는 경우 metric을 scrape 하도록 설정하였습니다.
# prometheus-server-conf.yaml
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: null
name: prometheus-server-conf
namespace: monitoring
data:
prometheus.yaml: |-
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 15s
rule_files:
- "/etc/prometheus-rules/*.rules"
alerting:
alertmanagers:
- scheme: http
static_configs:
- targets:
- "alertmanager-http.monitoring.svc:9093"
scrape_configs:
- job_name: 'kubernetes-nodes'
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:10255'
target_label: __address__
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_pod_node_name]
target_label: instance
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: (.+)(?::\d+);(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- job_name: 'kubernetes-services'
metrics_path: /probe
params:
module: [http_2xx]
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__address__]
target_label: __param_target
- target_label: __address__
replacement: blackbox
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
target_label: kubernetes_name
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- source_labels: [__meta_kubernetes_pod_container_port_number]
action: keep
regex: 9\d{3}
- job_name: 'kubernetes-cadvisor'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kube-state-metrics'
static_configs:
- targets: ['kube-state-metrics-http.monitoring:8080']
이번엔 위의 prometheus-server-conf에서 외부의 파일 경로로 대체한 rules의 파일을 configmap으로 작성해주도록 하겠습니다. 아래의 alerting rule들은 제가 주로 사용하는 alerting rule을 선별해 둔 것이고, alerting rule의 다양한 예시는 이곳을 참고하여 prometheus를 구성하는 환경에 맞게 세팅하도록 합니다.
# prometheus-rules.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-rules
labels:
name: prometheus-rules
namespace: monitoring
data:
alert-rules.yaml: |-
groups:
- name: Node
rules:
- alert: Kubernetes PV Error
expr: >
kube_persistentvolume_status_phase{phase=~Failed|Pending, job=kube-state-metrics} > 0
for: 5m
labels:
severity: critical
annotations:
summary: Kubernetes PersistentVolume error (pv: {{ $labels.persistentvolume }})
description: Persistent volume is in {{ $value }}
team: devops
- alert: Kubernetes PVC Pending
expr: >
kube_persistentvolumeclaim_status_phase{job=kube-state-metrics, phase=Pending} == 1
for: 5m
labels:
severity: warning
annotations:
summary: Kubernetes PersistentVolumeClaim pending (instance: {{ $labels.instance }})
description: PersistentVolumeClaim {{ $labels.namespace }}/{{ $labels.persistentvolumeclaim }} is pending
team: devops
- alert: Kubernetes Node Ready
expr: >
kube_node_status_condition{job=kube-state-metrics, condition=Ready,status=true} == 0
for: 5m
labels:
severity: critical
annotations:
summary: Kubernetes Node ready (node: {{ $labels.node }})
description: Node {{ $labels.node }} has been unready for a long time
team: devops
- alert: Node Out Of Memory
expr: >
((node_memory_MemTotal_bytes{job=kubernetes-service-endpoints} - node_memory_MemFree_bytes{job=kubernetes-service-endpoints}) / node_memory_MemTotal_bytes{job=kubernetes-service-endpoints}) * 100 > 90
for: 5m
labels:
severity: critical
annotations:
summary: Node memory usage > 90% (instance: {{ $labels.instance }})
description: {{ $value }}%
team: devops
- name: Pod
rules:
- alert: Container Cpu Usage
expr: >
sum(rate(container_cpu_usage_seconds_total{name!~.*prometheus.*, image!=, container!=POD, job=kubernetes-cadvisor}[5m])) by (container, namespace) / sum(container_spec_cpu_quota{name!~.*prometheus.*, image!=, container!=POD, job=kubernetes-cadvisor}/container_spec_cpu_period{name!~.*prometheus.*, image!=, container!=POD, job=kubernetes-cadvisor}) by (container, namespace) * 100 > 90
for: 5m
labels:
severity: critical
annotations:
summary: Container CPU usage > 90% (namespace: {{ $labels.namespace }}, container: {{ $labels.container }})
description: {{ $value }}%
- alert: Container Memory Usage
expr: >
(avg (container_memory_working_set_bytes{container!=POD, container!=, job=kubernetes-cadvisor}) by (container , namespace)) / (avg (container_spec_memory_limit_bytes{container!=POD, container!=, job=kubernetes-cadvisor} > 0 ) by (container, namespace)) * 100 > 90
for: 5m
labels:
severity: critical
annotations:
summary: Container Memory usage > 90% (namespace: {{ $labels.namespace }}, container: {{ $labels.container }})
description: {{ $value }}%
team: dev
- alert: Kubernetes Statefulset Down
expr: >
(kube_statefulset_status_replicas_ready{job=kube-state-metrics} / kube_statefulset_status_replicas{job=kube-state-metrics}) != 1
for: 5m
labels:
severity: critical
annotations:
summary: Kubernetes StatefulSet down (namespace: {{ $labels.namespace }}, statefulset: {{ $labels.statefulset }})
description: A StatefulSet went down
team: dev
- alert: Kubernetes Pod Not Healthy
expr: >
min_over_time(sum by (namespace, pod) (kube_pod_status_phase{job=kube-state-metrics, phase=~Pending|Unknown|Failed})[5m:]) > 0
for: 5m
labels:
severity: critical
annotations:
summary: Kubernetes Pod not healthy (namespace: {{ $labels.namespace }})(pod: {{ $labels.pod }})
description: Pod has been in a non-ready state for longer than a minute.
team: dev
- alert: Kubernetes Job Failed
expr: >
kube_job_status_failed{job=kube-state-metrics} > 0
for: 5m
labels:
severity: warning
annotations:
summary: Kubernetes Job failed (job: {{ $labels.job_name }})
description: Job {{ $labels.namespace }} / {{ $labels.job_name }} failed to complete
team: dev
여기까지 배포했으면 이제 진짜로 Prometheus를 배포해보도록 하겠습니다. 해당 예시에선 prometheus가 down 또는 delete 되더라도, 이전에 scrape 했던 metric을 보존하고 prometheus를 고유한 number로 관리하기 위해 statefulset으로 배포하도록 하겠습니다.
# prometheus-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: prometheus-volume
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 20Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data"
# prometheus-server-service.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus-server-http
namespace: monitoring
labels:
app: prometheus
annotations:
prometheus.io/scrape: "true"
spec:
selector:
app: prometheus
type: NodePort
ports:
- port: 9090
protocol: TCP
name: prometheus# prometheus-server-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: prometheus-server
namespace: monitoring
labels:
app: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
serviceName: prometheus-server-http
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: monitoring
securityContext:
runAsUser: 0
containers:
- name: prometheus
image: prom/prometheus:v2.20.1
args:
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention.time=15d"
- "--config.file=/etc/prometheus/prometheus.yaml"
- "--web.enable-admin-api"
ports:
- name: prometheus
containerPort: 9090
resources:
requests:
cpu: 1
memory: 1Gi
limits:
cpu: 1
memory: 1Gi
volumeMounts:
- name: prometheus-storage
mountPath: /prometheus
- name: prometheus-server-conf
mountPath: /etc/prometheus
- name: prometheus-rules
mountPath: /etc/prometheus-rules
volumes:
- name: prometheus-server-conf
configMap:
defaultMode: 420
name: prometheus-server-conf
- name: prometheus-rules
configMap:
name: prometheus-rules
volumeClaimTemplates:
- metadata:
name: prometheus-storage
namespace: monitoring
spec:
accessModes:
- ReadWriteOnce
storageClassName: manual
resources:
requests:
storage: 20Gi대부분은 기본적인 kubernetes 배포와 관련된 옵션들이기 때문에 다룰 필요가 없을 것 같지만, 몇 가지 유의해서 볼 부분만 살펴보도록 하겠습니다. 먼저 securityContext입니다. 현재 `runAsUser: 0`값을 주었는데, 이는 root의 권한으로 접근한다는 뜻입니다. 사실 이는 보안 측면에선 좋은 방법은 아니지만, root 권한을 주지 않을 경우 아래와 같은 에러를 만날 수 있기 때문에 편의상 예제의 목적으로 root 권한을 부여하였습니다.
"Error opening query log file" file=/prometheus/queries.active err="open /prometheus/queries.active: permission denied"만약 root 권한으로 컨테이너를 실행시키고 싶지 않다면 아래의 옵션으로 변경합니다. (구성중인 kubernetes 상황에 따라 위의 에러가 발생할 수 있습니다.)
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000다음으로 살펴볼 부분은 args입니다. args를 통해서 prometheus가 실행될 때 여러 옵션을 줄 수 있습니다. 현재 예시에서 넣어준 args는 아래와 같습니다.
- --storage.tsdb.path: prometheus가 수집한 metric을 저장할 경로입니다.
- --storage.tsdb.retention.time: prometheus가 scrape 한 metric을 며칠간 보관할지에 관한 옵션입니다. default 값은 15d입니다.
- --config.file: prometheus의 config 파일의 경로입니다. 해당 예시에선 configmap으로 작성하여 volumeMounts로 주입시켜 주었습니다.
- --web.enable-admin-api: prometheus의 admin api 활성화 옵션입니다. 혹여나 prometheus의 storage가 가득 찼을 경우에 api를 통해 storage를 비워주는 등의 기능을 제공합니다. 자세한 내용은 여기를 참고합니다.
자, 이제 prometheus가 배포되었습니다. 이제 아래와 같이 port-forward를 입력한 후, localhost:9090/graph로 접근해 보도록 하겠습니다.

localhost:9090/graph로 접속했을 때 위와 같은 화면이 보인다면 성공입니다. Execute 옆에 있는 버튼을 누르면 현재 prometheus가 수집하고 있는 metric의 종류를 볼 수 있고, 위의 입력창을 통해 직접 PromQL을 사용할 수도 있습니다. 또한 Graph 버튼을 눌러 그래프 형태로 metric을 보는 등 다양한 기능을 web을 통해서 사용할 수 있습니다.
🧑🏻💻 Alertmanager란
위에서 우리는 prometheus에서 prometheus-rules.yaml 파일에 알림이 발생하는 조건을 명시했었습니다. prometheus는 해당 조건에 부합하는 경우 알림을 발생시키고 해당 알림을 alertmanager로 전송하게 됩니다. 이때 alertmanager는 어떤 client로 알림을 전송할 것인지 또한 얼마나 자주 client로 알림을 전송할 것인지와 같은 알림 발송과 관련된 다양한 설정과 실질적인 알림 전송을 담당하고 있습니다. Alertmanager가 지원하는 대표적인 메신저로는 slcak, email, wechat, pagerduty, pushover, opsgenie, victorops과 custom하게 사용할 수 있는 webhook이 있습니다. 해당 포스팅에선 slack을 기준으로 배포해보도록 하겠습니다.
# alertmanager-config.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: alertmanager
namespace: monitoring
data:
config.yml: |-
global:
resolve_timeout: 5m
slack_api_url: ""
route:
group_by: ['alertname']
receiver: slack
group_wait: 10s
group_interval: 1m
repeat_interval: 4h
receivers:
- name: slack
slack_configs:
- channel: "general"
username: "Prometheus"
send_resolved: true
title: ""
text: ""
alertmanager의 configmap의 가장 기본적인 세팅부터 살펴보겠습니다.
route는 default 설정이 들어가는 부분입니다. route 하위에 있는 값들은 모두 따로 설정을 변경하지 않는 한 default 값으로 알림에 적용됩니다. 위의 코드에선 알림의 반복 주기에 관한 옵션이 들어있는데 아래와 같습니다.
1. group_wait
첫번째 알림을 보내기 전에 동일한 문제의 알림을 줄이기 위해 대기하는 시간입니다. 위의 코드 기준으로 10초동안 발생하는 알림을 모은 후에 client로 전송하게 됩니다.
2. group_interval
동일한 그룹에서 새로운 알림이 배치에 추가됐을 때 추가 알림을 보내기 전까지 대기하는 시간입니다. 여기서 group이란 위에서 group_by 배열에 들어가는 값을 집계 키로 잡아 그룹핑 되는 값들을 이야기합니다. group_by에 들어갈 수 있는 값으론 알림이 발생했을 경우 포함되는 label의 종류입니다.
예를 들어 동일한 alertname으로 이루어진 두개의 알림이 30초 간격으로 발생한다면, alertmanager는 두 개의 알림은 같은 그룹으로 인식하게 됩니다. 여기서 label의 값들마저 두 개의 알림이 모두 같다면(value 값이 같거나 다른 것은 판단 기준에 들어가지 않음), 두 개의 알림이 이전에 발생한 알림과 동일한 알림이라고 판단하고 repeat_interval의 시간까지 이와 같은 조건의 알림은 client로 전송하지 않습니다.
3. repeat_interval
group_interval에서 동일한 알림이라고 판단한 알림에 대하여 얼마만큼의 시간이 흐른 후에 동일한 알림을 다시 client로 재전송 할 것인지에 대한 옵션입니다.
이와 같이, 알림에 대하여 다양한 옵션이 존재하는 것은, 너무 많은 알림으로 인해 생기는 스트레스나 중복된 정보로 중요한 정보가 묻히는 것을 염려하기 때문입니다. 따라서 팀의 상황에 따라서 적절한 알림 빈도를 선택하는 것이 옳습니다.
다음은 alertmanager의 deployment와 service에 관한 코드입니다. 크게 특별한 부분은 없고, 위에서 배포한 configmap을 alertmanager에 mount 해서 args의 config.file로 넣어주도록 합니다.
# alertmanager-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager
template:
metadata:
name: alertmanager
labels:
app: alertmanager
spec:
containers:
- name: alertmanager
image: quay.io/prometheus/alertmanager:v0.21.0
imagePullPolicy: Always
resources:
requests:
cpu: 250m
memory: 500Mi
limits:
cpu: 250m
memory: 500Mi
args:
- "--config.file=/etc/alertmanager/config.yml"
- "--storage.path=/alertmanager"
ports:
- name: alertmanager
containerPort: 9093
volumeMounts:
- name: config-volume
mountPath: /etc/alertmanager
- name: alertmanager
mountPath: /alertmanager
volumes:
- name: config-volume
configMap:
name: alertmanager
- name: alertmanager
emptyDir: {}
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/path: "/metrics"
labels:
name: alertmanager
name: alertmanager-http
namespace: monitoring
spec:
selector:
app: alertmanager
type: ClusterIP
ports:
- name: alertmanager
protocol: TCP
port: 9093
targetPort: 9093여기까지 kubernetes 환경에 prometheus를 배포해보았습니다. 예제 코드를 하나하나 테스트하며 작성해서 생각보다 포스팅 시간이 오래 걸렸네요.🤣
다음 포스팅에선 좀 더 유용하고 다양한 metric을 얻기 위해 추가적인 exporter를 배포하는 방법에 대해서 살펴보도록 하겠습니다.
위의 코드들은 아래의 github url에서 확인하실 수 있습니다.
ooeunz/blog-code
Contribute to ooeunz/blog-code development by creating an account on GitHub.
github.com
'DevOps > Prometheus' 카테고리의 다른 글
| [Prometheus] Exporter 배포하기 (node-exporter, kube-state-metrics, actuator) (0) | 2021.02.12 |
|---|