이전 포스팅에서 비동기 처리를 하게 될 경우 non blocking 하게 servlet thread를 사용하는 방법에 대해서 살펴보았습니다. 하지만 여전히 문제가 남아있는 부분이 존재합니다. 바로 비동기 처리를 하는 worker thread입니다. worker thread가 만약 또 다른 서비스의 API를 호출하게 된다면 servlet thread는 반환되었지만 worker thread는 api 응답이 올 때까지 blocking 되어 대기상태가 되어야 합니다.
Spring 4.0에선 이러한 문제를 AsyncRestTemplate을 사용해서 해결할 수 있었습니다.
implementation("org.springframework.boot:spring-boot-starter-webflux")val asyncRestTemplate = AsyncRestTemplate(Netty4ClientHttpRequestFactory(NioEventLoopGroup(1)))AsyncRestTemplate을 사용할땐 반드시 Netty를 이용해주어야 합니다. 그렇지 않으면 non blocking io를 사용하지만 io가 발생할 때마다 새로운 thread를 생성하는 방식으로 문제를 해결하게 됩니다.
AsyncRestTemplate은 기존의 RestTemplate과 동일한 사용방법으로 사용할 수 있지만 현재 Depreated 상태입니다. Spring5에선 AsyncRestTemplate의 대안으로 WebClient라는 http client를 사용할 것을 권하고 있습니다. WebClient는 내부적으로 non bloking io 라이브러리인 Netty를 사용하고 있으며 reactive 방식을 채택하고 있습니다. WebClient의 사용방법을 알아보기 전에 Reactive programing이란 무엇인지부터 알아보도록 하겠습니다.
Reactive란?
Reactive하다는 것은 외부에서 어떠한 event가 발생했을 때 그에 대응하는 방식으로 코드를 작성하는 프로그래밍 패러다임입니다.
val iterable = listOf(1, 2, 3, 4, 5).iterator()
while (iterable.hasNext()) {
val result = iterable.next()
println("result=$result")
}
예를 들어서 Iterator의 next() 메서드는 data를 pull 해오는 방식입니다.
반면 reactive programing의 기초가 되었던 90년대에 나온 디자인 패턴인 observable pattern을 확인해보겠습니다.
※ 현재 Observableimplements는 현재 deprecated 되었기 때문에 java코드를 사용하겠습니다.
class IntegerObservable extends Observableimplements, implements Runable {
@Override
public void run() {
for (int i = 0; i< 1= 10; i++) {
setChanged();
notifyObservers(i); // iterator.next()와 달리 push하는 방식
}
}
}
class ObservablePattern() {
public static void main(String[] args) {
Observer ob = new Observer() {
@Override
public void update(Observable o, Object arg) {
System.out.println(arg);
}
}
IntegerObservable io = new IntegerObservable();
io.addObserver(ob);
io.run();
}
}위의 코드에서 IntegerObservable은 하나의 source이며 특정 시점에 notifyObservers() 메서드를 이용해서 event를 던지게 됩니다. (Data를 Push) 그리고 이러한 observable의 event를 관찰하고 있는 것이 바로 Observer(관찰자)이며, Observable은 addObserver() 메서드를 이용해서 Observer를 등록하게 됩니다.
이때 Observable에서 만들어내는 event는 하나의 observer만 등록할 수 있는 게 아니라 관심이 있는 다른 observer들이 여러 개 등록하여 멀티캐스트로 event를 전파할 수 있다는 장점이 있습니다.
하지만 observable 패턴은 한계를 가지고 있습니다. event가 종료되었다는 complete를 알려줄 수 있는 방법이 없고, Exception을 어떤 식으로 전파할 것이고, 받은 예외를 어떻게 처리할 것인지 등에 간한 아이디어가 패턴에 녹아져 있지 않습니다.
Reactive를 처음 만든 Microsoft 엔지니어들은 수많은 server와 client가 통신하는 현재의 상황에는 이러한 90년대 초에 나온 observable 패턴을 그대로 사용하기에는 한계가 있다고 판단하여 기존의 observable 패턴에 부족한 2가지를 새롭게 추가해서 확장된 observable 패턴을 개발하게 됩니다.
그게 바로 reactive입니다.
Reactive Streams
Reactive 진영에는 크게 두가지 큰 그룹이 존재합니다. 하나는 microsoft에서 시작해서 netflix에서 완성된 reactive x, 그리고 다른 하나는 spring에서 만든 reactor입니다.
ReactiveX
CROSS-PLATFORM Available for idiomatic Java, Scala, C#, C++, Clojure, JavaScript, Python, Groovy, JRuby, and others
reactivex.io
이 두가지 그룹은 모두 reactive-streams라는 하나의 표준을 지켜서 개발되었습니다. 그렇기 때문에 reactiveX와 reactor는 어느 정도 호환이 가능합니다. 그렇다면 reactive-streams는 어떤 표준을 정의하였을까요?
reactive-streams-jvm을 보면 표준 프로토콜을 확인할 수 있습니다.
GitHub - reactive-streams/reactive-streams-jvm: Reactive Streams Specification for the JVM
Reactive Streams Specification for the JVM. Contribute to reactive-streams/reactive-streams-jvm development by creating an account on GitHub.
github.com
아래는 reactive-streams-jvm의 문서를 발췌한 것입니다.
참고로 reactive에선 observable의 객체를 다음과 같은 이름으로 사용합니다.
Publisher ← Observable
Subscriber ← Observer

간략하게 요약하면 subscribe가 될때 onSubscribe() 메서드가 필수적으로 호출되어야 하며, 이후에 onNext() 메서드가 1번 또는 N 번까지 호출될 수 있으며, 이후에 onError() 혹은 onComplete()가 배타적으로 호출될 수 있다는 내용입니다.
Observable pattern의 Observable.addObserver(Observer)처럼 reactive에서도 Publisher.subscribe(Subscriber)와 같은 형태로 subscriber는 publisher를 구독할 수 있습니다.
val publisher = object : Publisher<Int> {
override fun subscribe(s: Subscriber<in Int>) {
s.onSubscribe(subscription)
}
}그런데 onSubscribe() 호출시에 반드시 parameter로 Subscription이라는 객체를 넘겨주어야 하는데요. 여기서 subscription이란 publisher와 subscriber사이에서 중계를 해주는 객체입니다.
subscriber는 subscription을 통해서 데이터를 요청하고, publisher는 data를 push 하게 됩니다.
(여기서 말하는 요청 이란 위에서 나온 iterable의 next() 메서드 같이 pull 방식으로 데이터를 요청하는 메서드가 아니라 backpressure 를 의미합니다)
Backpressure
Backpressure란 publisher와 subscriber 사이에 속도차가 발생하는 경우 이를 조정할 수 있도록 하는 것입니다. (실제로 data를 보내주는 건 publisher가 onNext() 메서드를 이용하여 보내주게 됨)
bakpresssure가 필요한 이유는 publisher가 data를 생산하는 속도에 비해 subscriber가 속도가 느린 경우 이를 조절하기 위해 필요하게 됩니다. 예를 들어 publisher가 데이터가 100만 개가 있고, subscirber가 1초에 한 개의 data만 처리할 수 있다면 subscriber가 모든 데이터를 처리하기까지 100만 초가 필요하게 됩니다. 그 사이에 데이터는 어떻게 될까요?
아마 data의 leak이 발생하거나 아주 큰 양의 buffer가 필요하게 될 것입니다.
이런 경우 data의 생성 속도 자체를 늦추는 것이 도움이 되기 때문에 subscriber가 수용할 수 있는 정도의 데이터를 backpressure로 요청하여 데이터의 양을 조절하게 됩니다. 예를 들면 아래와 같이 구현할 수 있을 것 같습니다.
val publisher = object : Publisher<Int> {
val iter = listOf(1, 2, 3, 4, 5).iterator()
override fun subscribe(s: Subscriber<in Int>) {
s.onSubscribe(
object : Subscription {
override fun request(n: Long) {
try {
var idx = 0
while (idx++ < n) {
if (iter.hasNext()) {
s.onNext(iter.next())
idx++
} else {
s.onComplete()
}
}
} catch (e: Exception) {
s.onError(e)
}
}
override fun cancel() {}
}
)
}
}코드의 깊이가 깊어져서 한눈에 알아보기 힘들지만 조금 뜯어보면 subscription에 backpressure로 들어온 수만큼 count를 하며 data를 push 해주고, 만약 모든 data를 push 하였다면 subscriber의 onComplete() 메서드를, 중간에 exception이 발생했다면 onError() 메서드를 호출해주도록 하는 코드입니다.
그렇다면 subscriber는 어떤 식으로 구현되어야 할까요? 이것 역시 간단하게 구현해보겠습니다.
val subscriber = object : Subscriber<Int> {
lateinit var subscription: Subscription
override fun onSubscribe(s: Subscription) {
subscription = s
subscription.request(1)
}
override fun onNext(t: Int?) {
subscription.request(1)
}
override fun onError(t: Throwable) {
println(t.message)
}
override fun onComplete() {}
}onSubscribe가 실행될 때 parameter로 받는 subscription 객체를 저장해 두고 이후에 onNext가 호출될 때마다 subscription 객체의 request를 이용해서 data를 요청하게 됩니다. (현재는 간략하게 test code로써 backpressure에 1개의 data만 요청하도록 해두었지만 실제론 buffer를 두어서 buffuer의 크기를 반을 유지하면서 데이터를 요청한다고 함)
자 그렇다면 최종적으로 다시 한번 실행 순서를 확인해보고 puslisher에 subscriber를 구독까지 추가하여 실행하는 코드를 확인해보겠습니다.

- p.subscribe(s)에서 subcriber는 publisher를 구독하게 됩니다.
- subscribe() 메서드에선 필수적으로 parameter로 들어온 subscriber의 onSubscribe() 메서드를 호출하게 됩니다.
- 이때 onSubscribe() 메서드에 parameter로 Subscription 객체를 넣어주게 됩니다.
- subscription 객체는 publisher와 subscriber의 중계 역할을 하는 object로 backpressure 기능을 가지고 있습니다.
- subscription은 request를 이용해 backpressure를 요청합니다.
- subscription의 request는 내부적으로 backpressure로 들어온 long의 수만큼 data를 push 해주게 됩니다.
- 이때 만약 더 이상 data가 없다면 onComplete()를 호출하고, exception이 발생한다면 onError()를 호출하게 됩니다.
fun main(args: Array<String>) {
val publisher = object : Publisher<Int> {
val iter = listOf(1, 2, 3, 4, 5).iterator()
override fun subscribe(s: Subscriber<in Int>) {
s.onSubscribe(
object : Subscription {
override fun request(n: Long) {
try {
var idx = 0
while (idx++ < n) {
if (iter.hasNext()) {
s.onNext(iter.next())
idx++
} else {
s.onComplete()
}
}
} catch (e: Exception) {
s.onError(e)
}
}
override fun cancel() {}
}
)
}
}
val subscriber = object : Subscriber<Int> {
lateinit var subscription: Subscription
override fun onSubscribe(s: Subscription) {
println("onSubscribe()")
subscription = s
subscription.request(1)
}
override fun onNext(t: Int) {
println("onNext(): $t")
subscription.request(1)
}
override fun onError(t: Throwable) {
println("onError()")
println(t.message)
}
override fun onComplete() {
println("onComplete()")
}
}
publisher.subscribe(subscriber)
}
위에서 pull 방식으로 했던 것과 같은 결괏값이 출력되는 것을 확인할 수 있습니다. 이와 같이 pull 방식과 push 방식처럼 표현 방법은 다르지만 결과는 같은 것을 duality(상대성: 궁극적으로 기능은 같지만 반대 방향으로 표현하는 것)라고 부르게 됩니다.
WebFlux
이제 reactive programing이 어떤 식으로 동작하는지 살펴보았으니까 WebFlux에 대해서 간략하게 언급하고 가도록 하겠습니다. 우리는 앞의 게시물에서 CompletableFuture를 이용해서 callback이 실행될 때 spring에서 servlet thread를 다시 불러와서 return 해주는 것을 확인했었습니다. 그렇다면 reactive는 spring에서 어떻게 활용할까요?
@GetMapping("/reactive")
fun reactive(): Mono<String> {
return Mono.just("This is reactive")
}그냥 Mono 혹은 Flux type을 return 하면 됩니다. 여기서 Mono와 Flux란 reactor에서 사용하는 reactive 객체로써 구현 객체를 타고 들어가면 우리가 위에서 확인했던 Publisher를 구현하고 있습니다. Spring에선 이러한 Publisher의 구현 객체를 controller 단에서 return 해주면 알아서 subscribe를 해주게 됩니다.

WebFlux는 기존의 spring mvc의 많은 핵심 component들을 공유하고 있기 때문에 기존의 mvc 스타일을 코드와 거의 유사하게 코드를 작성할 수 있습니다. 때문에 코드만으론 spring mvc와 webflux를 구분하기 어려울 정도입니다.
mvc와 webflux 간의 가장 중요한 차이는 빌드에 추가하는 의존성의 차이가 있는데 기존의 mvc에선 spring-boot-starter-web을 사용하였지만, WebFlux는 spring-boot-starter-webflux 의존성을 사용한다는 차이가 있습니다.
// spring mvc
implementation("org.springframework.boot:spring-boot-starter-web")
// spring webflux
implementation("org.springframework.boot:spring-boot-starter-webflux")WebFlux는 기본적으로 내장 서버가 tomcat이 아닌 event loop 기반의 netty가 사용됩니다. netty는 webflux와 같은 reactive web framework와 궁합이 잘 맞습니다. 하지만 spring mvc라고 해도 reactive type을 사용하지 못하는 것은 아닙니다. spring mvc도 위에처럼 Mono나 Flux를 return 할 수 있습니다.
다만 차이점은 WebFlux는 요청이 이벤트 루프로 처리되는 진짜 리액티브 웹 프레임워크인 반면 spring mvc는 multi thread에 의존하여 다수의 요청을 처리하는 servlet 기반의 web framework라는 사실입니다.
Operation
Mono와 Flux는 Publisher를 이미 구현한 type입니다. 그리고 이미 utility성 메서드들이 많이 구현되어 있습니다. 잠시 operator에 대해서 살펴보고 가겠습니다.
SteopVerifier
StopVerifier는 해당 리액티브 타입을 구독한 다음 stream을 통해 전달되는 데이터에 assetion을 적용하여 결과를 확인할 수 있습니다. 아래의 예제들의 결과는 StepVerifier를 이용해서 확인해보도록 하겠습니다.
Join
@Test
fun join() {
val peopleFlux = Flux.just("noah", "kevin", "elly")
StepVerifier.create(peopleFlux)
.expectNext("noah")
.expectNext("kevin")
.expectNext("elly")
.verifyComplete() // people이 완전히 같은지 확인
}
fromIterable
@Test
fun fromIterable() {
val people = listOf("noah", "kevin", "elly")
val peopleFlux = Flux.fromIterable(people)
StepVerifier.create(peopleFlux)
.expectNext("noah")
.expectNext("kevin")
.expectNext("elly")
.verifyComplete()
}
range
일정 범위 값을 생성하는 카운터 Flux
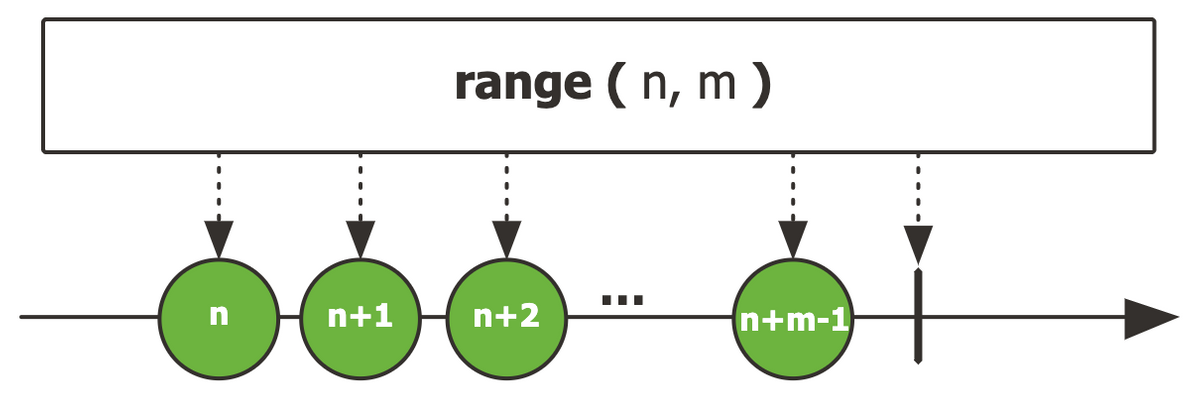
@Test
fun range() {
val people = Flux.range(1, 3);
StepVerifier.create(people)
.expectNext(1)
.expectNext(2)
.expectNext(3)
.verifyComplete();
}
inverval
방출되는 시간이나 간격 주기를 설정하여 증가 값을 방출하는 Flux
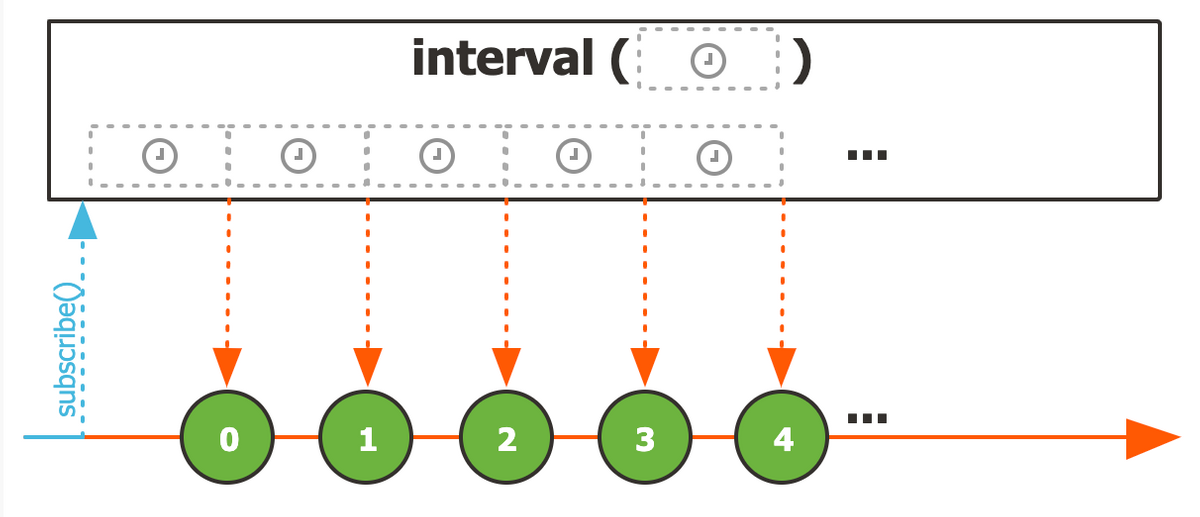
@Test
fun interval() {
val people = Flux.interval(Duration.ofSeconds(1))
.take(3); // 값을 제한하지 않으면 무한정 실행됨
StepVerifier.create(people)
.expectNext(0L) // 0부터 시작함
.expectNext(1L)
.expectNext(2L)
.verifyComplete();
}
다음은 reactive type을 조합하는 operator 들입니다.

map
public final <V> Flux<V> map(Function<? super T, ? extends V> mapper)map은 단일 값을 V타입으로 반환하는 operator입니다. 그래서 map은 각 항목이 Flux로부터 발행되었을 때 동기적으로 매핑이 수행됩니다.
@Test
fun map() {
val profileFlux: Flux<Profile> = Flux
.just("noah 25", "kevin 27", "elly 20")
.map {
val split = it.split("\\s").toTypedArray()
Profile(split[0], split[1])
}
StepVerifier.create(profileFlux)
.expectNext(Profile("noah", "25"))
.expectNext(Profile("kevin", "27"))
.expectNext(Profile("elly", "20"))
.verifyComplete()
}
flatMap
public final <R> Flux<R> flatMap(Function<? super T, ? extends Publisher<? extends R>> mapper)반면 flatMap은 T유형의 단일 값을 R유형의 Publisher로 변환합니다. 그리고 이러한 내부의 Publisher를 단일 Flux로 병합합니다. flatMap은 map operator와 달리 비동기적으로 수행된다는 특징이 있습니다. 따라서 subscribeOn() 메서드를 이용하여 reactive type의 변환을 병렬적으로 수행할 수 있습니다.
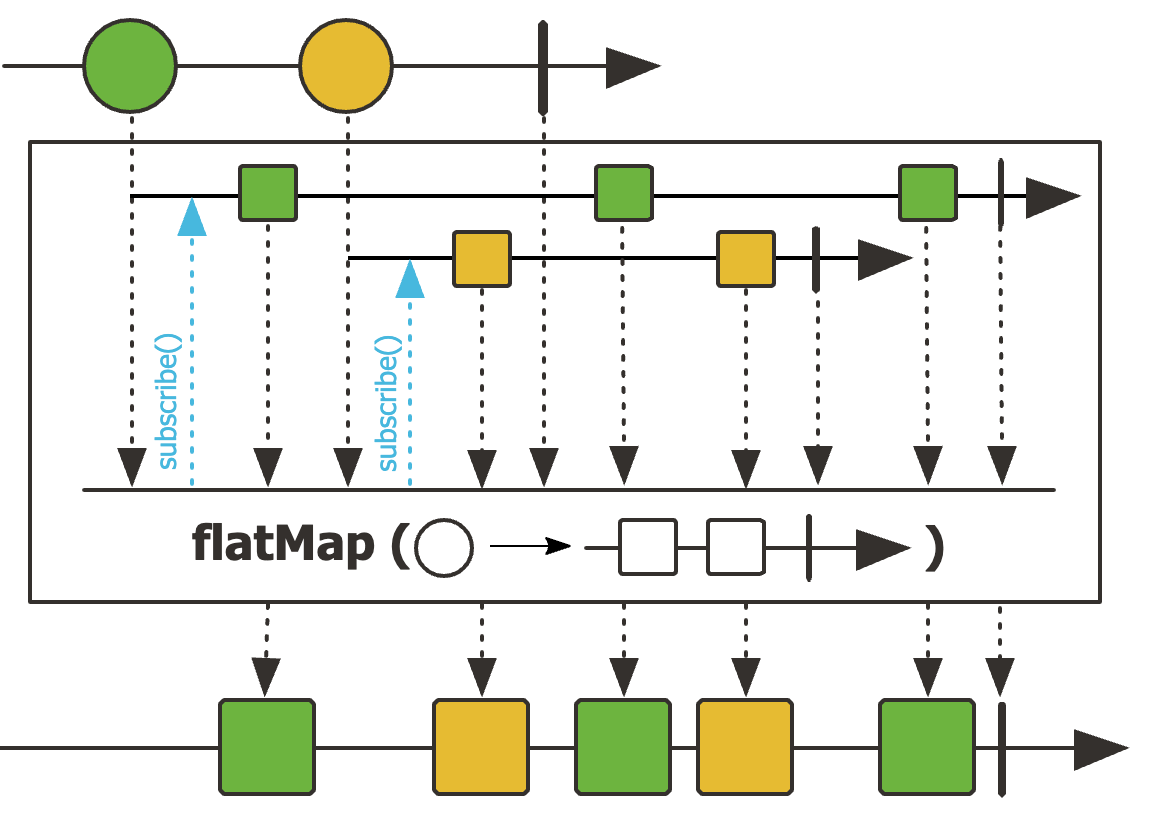
@Test
fun flatmap() {
val profileFlux = Flux
.just("noah 25", "kevin 27", "elly 20")
.flatMap {
Mono.just(it)
.map {
val split = it.split("\\s")
Profile(split[0], split[1])
}
.subscribeOn(Schedulers.parallel())
}
val profiles = listOf(
Profile("noah", "25"),
Profile("kevin", "27"),
Profile("elly", "20")
)
StepVerifier.create(profileFlux)
.expectNextMatches { profiles.contains(it) }
.expectNextMatches { profiles.contains(it) }
.expectNextMatches { profiles.contains(it) }
.verifyComplete()
}코드를 잠시 살펴보면
1. flatMap 안에서 String 객체를 Mono type으로 변환합니다.
2. Mono에 map() operator를 이용하여 String 객체를 Profile 객체로 변환합니다.
3. subscribeOn() 메서드를 호출하면서 parameter로 넘겨주는 Scehdulers에 따라 병렬 스레드로 처리할 수 있습니다.
단, 작업이 병렬적으로 수행되기 때문에 어떤 작업이 먼저 끝날지 알 수 없습니다.
Schedulers class는 아래와 같은 동시성 모델을 지정할 수 있습니다.
| 메서드 | 설명 |
| .immediate() | 현재 스레드에서 구독을 실행함 |
| .single() | 하나의 재사용 가능한 스레드에서 구독을 실행함. 모든 호출자에 대해 동일한 스레드를 재사용함. |
| .newSingle() | 매 호출마다 전용 스레드에서 구독을 실행함. |
| .elastic() | 새로운 작업 스레드가 생성되며, 유휴 스레드는 제거됨. |
| .parallel() | 고정된 크기의 풀에서 가져온 스레드에서 구독을 실행함. cpu코어의 개수가 크기가 됨. |
이외에도 정말 많은 operator들이 존재합니다. 더 자세한 내용은 reactor 문서에서 확인할 수 있습니다.
Flux (reactor-core 3.4.10)
projectreactor.io
WebClient
네... 드디어 도착했습니다. 이제 WebClient에 대해서 살펴보도록 하겠습니다. 사실 WebClient api를 익히는 것은 그리 어려운 것이 아닙니다. 다만 앞에서 언급했던 reactive programing이 어떤 문제를 해결하려고 했고, 어떤 operator들을 사용하는지와 같은 것들만 알고 있다면 말이죠.

이 포스팅의 제일 처음에 언급했던 것처럼 WebClient는 non-blocking io를 지원하는 http client입니다. 내부적으로는 netty를 사용하고 있기 때문에 event loop방식으로 동작하고 reactive type인 mono와 flux를 return 하는 http client입니다.
WebClient를 사용하는 패턴을 간략하게 표현하면 아래와 같습니다.
- WebClient 인스턴스를 생성 또는 주입합니다.
- HTTP method 지정합니다.
- 요청을 보낼 URI, Header, Body를 지정합니다.
- 요청을 제출합니다.
- 응답을 소비(사용)합니다.
그럼 간단하게 Get method와 Post method의 사용 방법에 대해서 살펴보도록 하겠습니다.
GET
@Test
fun get() {
val id = "apple"
val fruit = WebClient.create()
.get()
.uri("localhost:8080/fruits/{id}", id) // 요청을 정의함
.retrieve() // 요청을 실행함
.bodyToMono(Fruit::class.java) // 응답 몸체의 payload를 Mono 형태로 추출함
fruit
.timeout(Duration.ofSeconds(1)) // 1초 이상 걸리게 되면 subscribe에 두번재 인자로 지정된 에러 핸들러가 실행됨
.subscribe { println(it) }
}요청은 retrieve() 대신 exchange()을 사용할 수 있습니다. exchage()는 RestTemplate을 ResponseEntity와 비슷한 객체로 header의 정보까지 포함하고 있는 response 객체입니다.
POST
@Test
fun post() {
val fruitMono = Mono.just(Fruit("파인애플"))
val fruit = WebClient.create()
.post()
.uri("localhost:8080/fruits")
.body(fruitMono, Fruit::class.java)
.retrieve()
.bodyToMono(Fruit::class.java)
fruit.subscribe { println(it) }
}Post method에선 body에 publisher type의 객체를 넣어서 http body를 넣어줄 수 있습니다. 이때 만약 Mono나 Flux type이 아니라 domain 객체라면 bodyValue() 메서드(spring 2.2.0 이하에선 syncBody)를 사용할 수 있습니다.
추가적으로 현재는 응답 payload로 Fruit class를 사용하고 있지만 비어져 있는 응답 papyload 받기 위해선 Void class를 사용할 수 있습니다.
@Test
fun voidPost() {
val fruitMono = Fruit("파인애플")
val fruit = WebClient.create()
.post()
.uri("localhost:8080/fruits")
.bodyValue(fruitMono)
.retrieve()
.bodyToMono(Void::class.java)
fruit.subscribe { println(it) }
}
이외에도 다양한 메서드가 존재하지만 이제 api 문서를 읽어보면 어떤 역할을 하는 메서드인지 알 수 있을 것 같아서 여기까지 줄이도록 하겠습니다 ㅎㅎ (사실 더 포스팅할 힘이 없음...)
사실 kotlin을 이용해서 WebFlux 개발을 한다면 이렇게 Mono와 Flux를 사용하는 방법보다 좀 더 우아한 방법이 존재합니다. 바로 coroutine을 이용하는 방법인데요 ㅎㅎ
이 부분은... 다음에 다시 기회가되면 포스팅 해보도록 하겠습니다 :)
'Server > Spring (Boot & Framework)' 카테고리의 다른 글
| [Spring] 비동기 처리시 blocking 되는 servlet thread 관리 (1) | 2021.09.25 |
|---|---|
| [Spring] Spring Batch: 대용량 데이터를 처리하는 프레임워크 (0) | 2020.06.26 |
| [Spring] Reactive Spring WebFlux: Tomcat과 Netty (0) | 2020.06.22 |
| [Spring] Bean Scope와 Bean Life Cycle (0) | 2020.05.26 |
| [Spring] iBatis/MyBatis: 쿼리 return결과 (0) | 2020.04.08 |