Stream Processing
스트림 프로세싱이란 데이터들이 지속적으로 유입되고 나가는 과정에서 이 데이터에 대한 분석이나 질의를 수행하는 것을 의미합니다. 즉 스트림 프로세싱은 데이터가 이동 중이거나, 생성되어 수신되는 즉시 처리하기 때문에 실시간 분석이라고 불리기도 합니다. 아래의 이미지와 같이 스트링 프로세싱을 사용하기 전에는 주로 데이터를 Database나 File System과 같은 대용량 저장소에 저장한 후, 필요에 따라 애플리케이션이 쿼리를 수행하거나 분석을 하는 등 배치 처리 형태를 띄고 있었습니다.
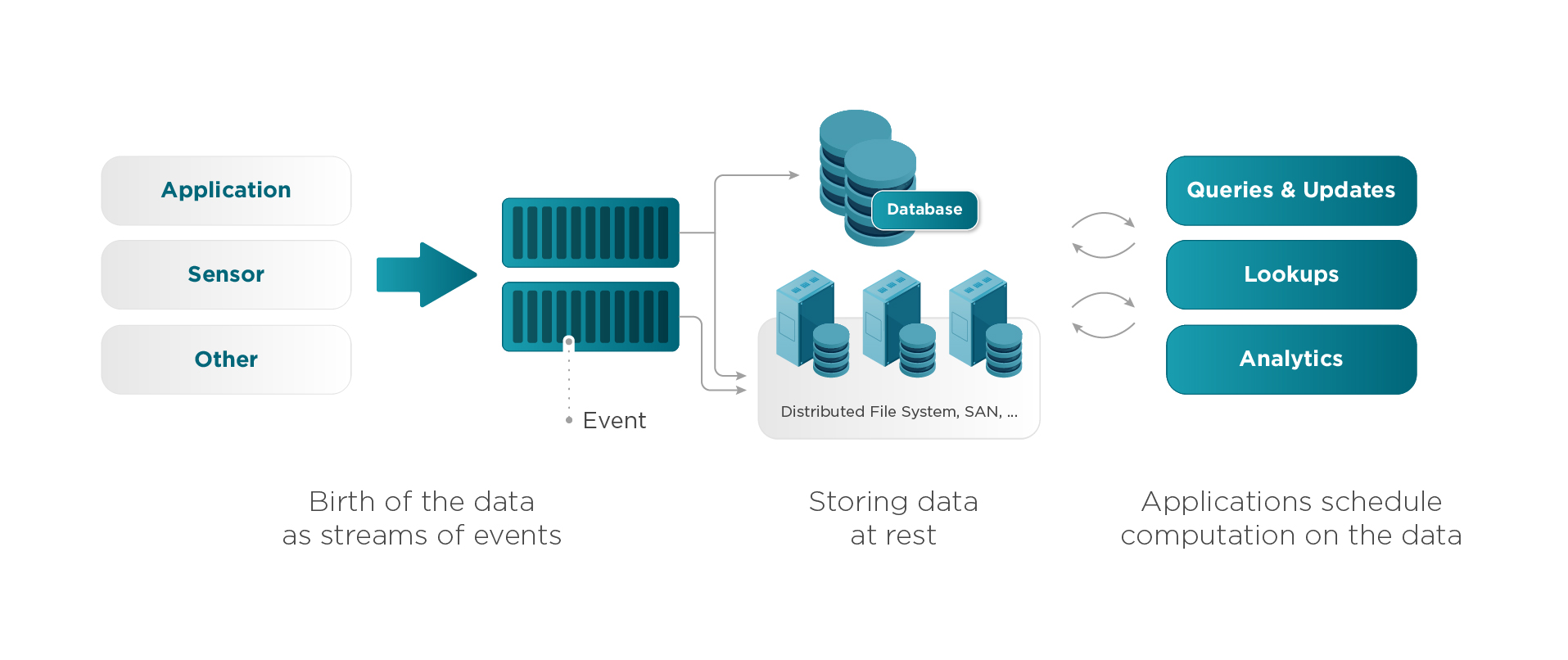
하지만 빅데이터 붐이 일어나고 스트림 프로세싱이 등장하고부터 이러한 데이터 처리 패러다임이 많이 바뀌었는데, 기존의 배치 형태를 띠고 있던 데이터 처리 파이프라인이 실시간 적이고 지속적으로 데이터를 처리하고 분석하게 되었습니다. (배치를 사용하지 않는 것이 아니라, 스트림 처리 시스템과 배치 처리 시스템을 모두 갖추어서 실시간과 정확성 모두 높이는 형태로 발전하였습니다)
스트림 프로세싱에서는 스트림에서 이벤트가 발생하면 스트림 프로세싱 애플리케이션이 즉각적으로 그 이벤트에 반응하게 되고, 해당 데이터를 통계 내거나 나중에 사용하기 위해 저장하는 등 다양한 형태로 해당 이벤트를 처리합니다.

이와 같이 스트림 프로세싱은 실시간으로 데이터를 분석하고 이벤트 중심으로 데이터를 처리하기 때문에 오늘 날 개발자가 빅데이터 처리에 신경 써야 할 많은 부분들을 손쉽게 해결해줍니다. 스트림 프로세싱의 장은 아래와 같습니다.
- 스트림 프로세싱은 애플리케이션과 분석이 즉각적으로 반응합니다. "Event Happen" -> "Analytics" -> "Action"의 과정에 지연이 거의 없습니다. 때문에 분석과 액션은 항상 의미 있는 데이터를 반영합니다.
- 스트림 프로세싱은 데이터를 저장한 후에 분석하는 것이 아니기 때문에 일반적으로 다른 정적 데이터 프로세싱 시스템보다 더 큰 데이터 용량을 다룰 수 있습니다.
- 스트림 프로세싱은 모든 데이터를 주기적으로 계산하는 배치와 정적 데이터 분석과 대조적으로 지속적으로 들어오는 데이터를 점차적으로 분석하기 때문에 실시간 처리에 최적화되어있습니다.
- 스트림 프로세싱은 애플리케이션은 자기 자신의 데이터와 상태를 유지하기 때문에 대규모 공유 데이터베이스에 대한 의존성을 줄일 수 있습니다. 이러한 방식은 MSA 방식에 친화적입니다.
Stateful Stream
스트림을 처리 하다보면 이전 스트림을 처리한 결과를 참조해야 하는 경우가 있습니다. 이런 류의 처리 방식을 상태 기반처리라고 합니다. 상태 기반 스트림 처리를 하기 위해서는 애플리케이션의 처리 결과를 저장할 상태 저장소(state store)가 필요합니다. 이때 스트림 프로세싱 애플리케이션이 이 저장소를 관리하면 내부 상태 저장소라고 하고, Database와 같은 별도의 상태 저장소를 사용하게 되면 외부 상태 저장소라고 합니다.
이와 반대로 무상태(stateless) 스트림 프로세싱은 이전 스트림의 처리 결과와 관계없이 현재 애플리케이션에 도달한 스트림만을 기준으로 처리하는 것을 말합니다.

Kafka Streams
kafka streams은 kafka 0.10.0.0 버전과 함께 공개된 스트림 프로세싱으로 주요한 특징은 아래와 같습니다.
※ 당시 2016년 3월 10일 Confluent(LinkedIn에서 Apache Kafka를 최초 개발한 사람들이 세운 회사)에서 게시한 포스팅
Introducing Kafka Streams: Stream Processing Made Simple - Confluent
Confluent, founded by the creators of Apache Kafka, delivers a complete execution of Kafka for the Enterprise, to help you run your business in real time.
www.confluent.io
- 카프카 스트림즈는 카프카에 저장된 데이터를 처리하고 분석하기 위해 개발된 클라이언트 라이브러리입니다. 다른 일반적인 스트링 프로세싱들은 '실행 프레임워크'인 반면 카프카 스트림즈는 라이브러리이기 때문에 사용자가 수동으로 구동하며, 특정 프레임워크에 탑재하여 실행할지 등을 전적으로 개발자가 결정할 수 있습니다. 즉 기존의 애플리케이션에서 쉽게 추가하고 사용할 수 있습니다.
- Apache Kafka 이외의 외부 dependencies에 의존성이 없습니다. 카프카 파티셔닝 모델을 사용하고 수평적으로 확장이 가능합니다. 또한 동시에 메시지 순서를 강력하게 보장합니다.
- fault-tolerant 로컬 상태 저장소를 지원하기 때문에 빠르고 효율적인 저장 작업이 가능합니다.
- 스트림 처리 중간에 클라이언트나 kafka broker에 장애가 발생하더라도 스트림에 대해선 1번만 처리합니다.
- millisecond 단위로 처리 지연을 보장하기 위해서 한 번에 하나의 레코드만 처리합니다.
- 수준의 스트림 DSL(Domain Specific Language)을 지원하고, 저수준의 프로세싱 API도 지원합니다.
Stream Processing Topology
카프카 스트림즈는 스트림 처리를 하는 프로세스들이 서로 연결되어 토폴로지(topology)를 만들어서 처리하는 API입니다. 따라서 일반 프로세스 노드에서 현재 레코드를 처리하는 동안 다른 원격 시스템에서도 접근할 수 있습니다. 이렇게 처리된 결과는 kafka로 다시 스트리밍 되거나 외부 시스템에 기록될 수 있습니다.
kafka stream topology에서 사용되는 용어
- Stream : 스트림은 카프카 스트림즈에서 제공하는 가장 중요한 추상화입니다. 카프카 스트림즈 API를 사용해 생성된 토폴로지로 끊임없이 전달되는 데이터 세트를 의미합니다. 스트림에 기록되는 단위는 키-값 형태를 띄고 있습니다.
- Stream processing application : 카프카 스트림 클라이언트를 사용하는 애플리케이션으로 하나 이상의 토폴로지를 처리하는 로직을 의미합니다.
- Stream Processor : 프로세서 토폴로지를 이루는 하나의 노드를 의미합니다. 여기서 노드는 프로세서 형상에 의해 연결된 하나의 입력 스트림으로부터 데이터를 받아서 변환한 다음 다시 연결된 프로세서에 보내는 역할을 합니다.
Processor Topology
- Source Processor : 소스 프로세서란 위쪽으로 연결된 프로세서가 없는 프로세서를 말합니다. 이 프로세서는 하나 이상의 카프카 토픽에서 데이터 레코드를 읽어서 하위 프로세서에게 전달합니다.
- Sink Processor : 해당 토폴로지 아래쪽에 프로세서가 없는 것을 말합니다. 이 프로세서는 상위 프로세서로부터 받은 데이터 레코드를 카프카 특정 토픽에 저장합니다.
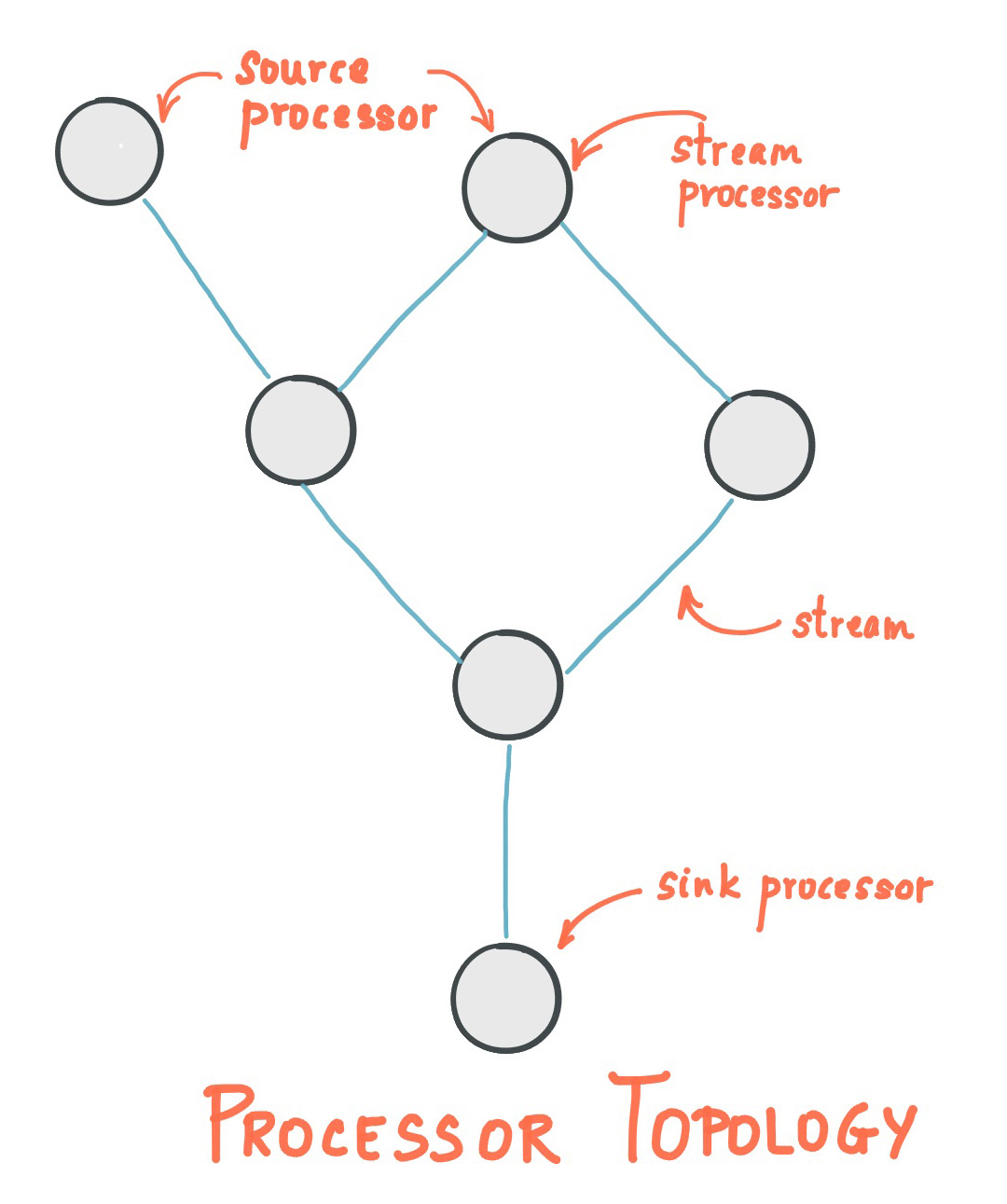
카프카 스트림즈는 Source Processor와 Sink Processor를 만드는 두 가지 방법을 제공합니다. 그 중한 가지는 Kafka Stream DSL로 데이터를 처리할 때 공통적으로 필요한 연산자 map, filter, join, aggregations와 같은 데이터 프로세싱 메서드를 제공하고, 다른 하나는 lower-level Processor API를 제공해서 개발자가 직접 사용자 지정 프로세서를 정의 / 연결하고 상태 저장소를 다룰 수 있습니다.
processor topology는 스트림 처리 코드의 추상화된 개념입니다. 실제로 런타임시에는 토폴로지가 애플리케이션 내에서 인스턴화 되고 복제되어 병렬적으로 처리되게 됩니다.
그럼 간단하게 input-stream이라는 토픽으로부터 들어온 메시지를 실시간으로 output-stream 토픽으로 옮기는 코드를 작성해보겠습니다.
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class Pipe {
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-pipe");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
final StreamsBuilder builder = new StreamsBuilder();
builder.stream("input-stream").to("output-stream");
final Topology topology = builder.build();
System.out.println(topology.describe());
final KafkaStreams streams = new KafkaStreams(topology, props);
streams.start();
stream.close();
}
}먼저 java.util.Properties를 사용해서 프로세스에 필요한 설정 값을 입력하도록 하겠습니다.
- StreamsConfig.APPLICATION_ID_CONFIG : 카프카 클러스터 내의 스트림즈 애플리케이션을 구분할 때 사용하는 값으로 유일해야합니다.
- StreamsConfig.BOOTSTRAP_SERVERS_CONFIG : 스트림 애플리케이션이 접근할 브로커의 ip와 port를 입력해줍니다.
- StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG : 토픽에서 다룰 데이터의 'key' 형식을 지정해줍니다.
- StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG : 토픽에서 다룰 데이터의 'value' 형식을 지정해줍니다.
설정을 완료한 다음에는 입력 소스로부터 어떤 작업들이 수행할지를 지정하는 토폴로지를 생성합니다. 토폴로지는 StreamsBuilder를 사용하게 되는데 그 과정으로 먼저 StreamsBuilder를 생성한 다음 input-stream 토픽으로부터 입력 스트림을 생성하고 output-stream 토픽으로 전달하도록 설정해줍니다. 최종적으로 토폴로지를 만들기 위해 빌더에서 build() 메서드를 호출합니다. (만들어진 토폴로지를 확인하기 위해서는 .describe() 메서드를 호출하면 됩니다.)
이제 생성한 토폴로지 객체와 프로퍼티 객체를 사용해서 스트림즈 객체를 생성하면 실제 동작하는 카프카 스트림즈 애플리케이션을 만들 수 있습니다. 그리고 start() 메서드를 호출해서 스트림즈 작업을 시작하고 close() 메서드를 호출해서 종료하게 됩니다.
방금의 예제는 한쪽 토픽에 있는 데이터를 그대로 다른 쪽으로 옮기는 파이프 프로세스였습니다. 이번에는 한쪽 토픽에서 읽은 데이터를 공백 기준으로 분리해서 값으로 다른 토픽에 저장하는 코드를 작성해보도록 하겠습니다. 이때 사용하는 KStream 메서드는 다음과 같이 크게 2가지가 있습니다.
- flatMap : 새로운 스트림을 만들 때 키와 값 모두 새롭게 만들어서 사용할 수 있습니다.
- flatMapValues : 새로운 스트림을 만들때 키는 변경할 수 없고 값만 변경해서 만들 수 있습니다.
위의 두 메서드는 모두 이전의 스트림 상태를 참고하지 않으므로 무상태 오퍼레이터라고 합니다.
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.KStream;
import java.util.Arrays;
import java.util.Properties;
public class LineSplit {
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-linesplit");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
final StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("streams-plaintext-input");
source.flatMapValues(value -> Arrays.asList(value.split("\\W+"))).to("streams-linesplit-output");
final Topology topology = builder.build();
final KafkaStreams streams = new KafkaStreams(topology, props);
}
}source 스트림에 flatMapValues 메서드를 사용해서 새로운 스트림을 만들고, flatMapVallues 메서드에 전달된 ValueMapper는 소스 스트림의 각 데이터에 적용되서 새로운 값을 만듭니다.
'Big Data > Kafka' 카테고리의 다른 글
| [Kafka] Consumer: kafka broker로부터 메시지 가져오기 (0) | 2020.07.27 |
|---|---|
| [Kafka] Producer: kafka broker로 메시지 보내기(sync, async) (0) | 2020.07.23 |
| [Kafka] 데이터 모델: topic, partition, replication (0) | 2020.07.07 |
| [Kafka] 카프카의 고성능 디자인 모델 (0) | 2020.07.06 |
| [Kafka] Zookeeper: 분산 애플리케이션을 관리하는 코디네이션 시스템 (0) | 2020.07.06 |