앞선 포스팅에서 살펴봤듯이 카프카는 크게 메시지를 카프카로 전송하는 프로듀서, 메시지를 저장하고 있는 카프카(브로커), 메시지를 가져가는 컨슈머가 있다고 했습니다. 그리고 마지막으로 카프카와 떨어질 수 없는 코디네이션 애플리케이션인 주키퍼zookeeper가 있습니다.
주키퍼는 중앙에서 분산 application을 관리하는 코디네이션 애플리케이션으로 카프카의 상태 관리는 목적으로 합니다. 카프카는 주키퍼와 긴밀하게 통신을 하기 때문에 카프카를 사용하기 위해서는 주키퍼의 사용이 필수적입니다.
원래 주키퍼는 하둡Hadoop의 서브 프로젝트 중 하나였습니다. 대용량 분산 처리 애플리케이션인 하둡에서는 중앙에서 분산 애플리케이션을 관리하는 코디네이션 애플리케이션이 필요하기 시작했고, 서브 프로젝트로 주키퍼 개발을 시작하게 되었습니다. 하지만 2011년 1월에 드디어 주키퍼는 아파치 탑 레벨 프로젝트로 승격되었고 현재는 아파치 카프카뿐만 아니라 다양한 애플리케이션에서 사용되고 있습니다.
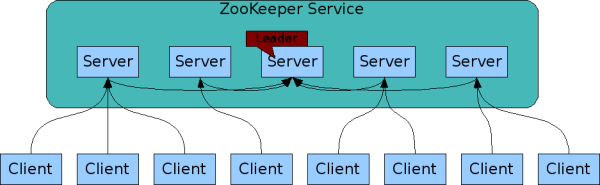
위의 이미지와 같이 주키퍼는 여러 대의 서버를 클러스터 형태로 구성하게 됩니다.(주키퍼에서는 이와 같은 클러스터를 앙상블이라고 합니다.) 그 후 여러 분산 애플리케이션을 클라이언트로, 주키퍼 서버들과 커넥션을 맺은 후 상태 정보를 주고받게 됩니다. 이와 같은 상태 정보들은 주키퍼 내부의 지노드znode라고 불리는 곳에 키-값(key: value)의 형태로 저장되게 됩니다.
지노드란 주키퍼 내에 데이터를 저장하는 공간의 이름을 지칭하는 단어로, 일반 컴퓨터의 폴더 구조와 흡사합니다.

가장 루트 디렉토리는 /로 표현하고 그 밑에 app1과 app2와 같은 하위 경로를 가지고 있고, 그 밑에 p_1와 같은 구조를 이루고 있습니다. 지노드는 데이터 변경에 의한 유효성 검사를 하기 위해 버전 번호를 관리하게 되는데, 그에 따라 지노드의 데이터가 변경될 때마다 지노드의 버전 번호가 증가하게 됩니다.
또한 주키퍼에 저장되는 데이터는 모두 메모리에 저장되어 처리량이 매우 크고 빠릅니다.
위에서 주키퍼는 앙상블로 이루어진다고 했는데, 앙상블 내의 노드 중 과반 수 이상이 살아있다면 지속적으로 서비스를 할 수 있습니다. 예를 들어 5개의 노드로 이룯어진 앙상블이 있을 경우 2개의 노드가 다운되더라도 과반 수 이상이 살아있기 때문에 지속적으로 서비스가 가능합니다. 즉, 앙상블 구성의 숫자가 많을수록 과반수 역시 증가하므로 장애가 발생하더라도 장애에 대응할 수 있습니다.
과반수 방식을 적용하기 때문에 주키퍼는 홀수로 서버를 구성해야합니다.
주키퍼는 아래의 url에서 다운받을 수 있고, 또는 docker를 이용해서 카프카와 함께 구성할 수 있습니다.
Apache ZooKeeper
'Big Data > Kafka' 카테고리의 다른 글
| [Kafka] Consumer: kafka broker로부터 메시지 가져오기 (0) | 2020.07.27 |
|---|---|
| [Kafka] Producer: kafka broker로 메시지 보내기(sync, async) (0) | 2020.07.23 |
| [Kafka] 데이터 모델: topic, partition, replication (0) | 2020.07.07 |
| [Kafka] 카프카의 고성능 디자인 모델 (0) | 2020.07.06 |
| [Kafka] 카프카 기본 개념: 실시간 비동기 스트리밍 솔루션 (0) | 2020.07.03 |